Last year in August, Kaanu was launched in BR Hills. Kaanu is a South Indian Adivasi Knowledge Centre.
The people behind Kaanu has been collecting and annotating relevant publications for many years now. This had to come online and that’s how I got involved.
Obsidian
Prashanth and Werner had already been curating and annotating a large bibliography using Wikindx here. Not coincidentally, I was the one to set this up on the server. Wikindx is built for bibliographies and has been developed since 2003. But time has taken its toll and wikindx is very much outdated in its appearance, even though there are quite frequent releases.
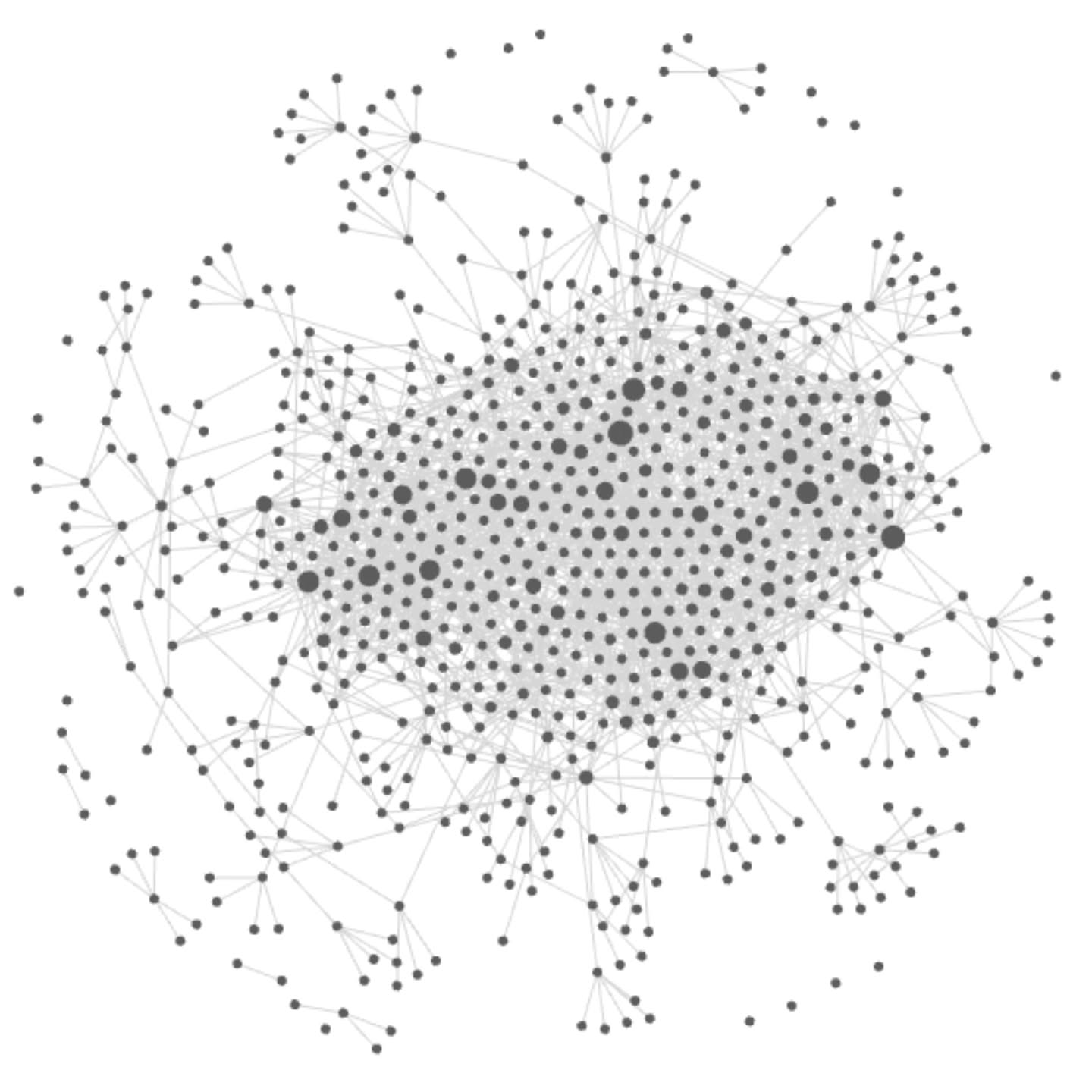
Enter Obsidian. Prashanth has been maintaining P’s own digital garden on obsidian. And for Kaanu too there was a separate instance. Apart from the fact that Obsidian allows quickly creating notes and linking them to each other, it has a fantastic graph view that allows visualizing the extent of the knowledge (as you can see in the image at the top of this post).
And thus, it was decided we would import the annotated bibliography to Obsidian.
The first workflow
The workflow was optimized for Werner’s (WS) comfort.
Sourcing
WS would keep a track of all new (and old) articles on the topic, and download a PDF copy whenever possible.
Depending upon the topic, Google Alerts might be useful to find new articles. It can give lots of false positives if the keyword you’re tracking on Alerts is rather generic.
Annotation
WS would then use the Inspector tool on Mac to add keywords to each PDF.
Synchronization
This is the part where we had the most trouble. WS was storing all the PDFs on iCloud drive and I thought it would be trivial to synchronize that with my computer or the server.
Turns out I was very wrong. Apple makes it extremely painful to do that.
Firstly, I needed an Apple account. Long ago when I had an iPhone I had an Apple account. That account has been locked due to inactivity. I called Apple support who were extremely kind and helpful, but unfortunately they also couldn’t reactivate the old account. So I ended up creating a new account (which was possible only after I called them on phone because earlier the Apple website simply wouldn’t let me create a new account).
Now, I had to find a way to synchronize the drive with my computer.
One common option on Linux is something called iCloud for Linux. But this seems to be just a wrapper to the website and doesn’t really perform any better than the going to icloud.com on the browser itself.
There is a tool called rclone which is supposed to actually be able to mount the drive locally. But in the deadline week, following Murphy’s law, rclone was not working with iCloud. Even though I followed the workaround and built it from source code, it turns out that rclone doesn’t support cloning a shared folder. I spent a few hours trying to reverse engineer the API and add support for shared folder, but I was running out of time.
Eventually I decided to just download all files using the browser, via icloud.com. This was very painful.
The challenge was that there were 1600+ files and the web version of iCloud doesn’t seem to have written for such large folders. To load the folder itself would take a few minutes as the browser makes a network request each for every file. The browser would repeatedly become unresponsive too.
I noticed that this was because the site was also trying to load thumbnail images for all the files. So, I disabled image loading in Firefox by changing permissions.default.image to 2 in about:config. This made the site more snappy, even though it still had to make 1 network request for each file.
There was no way to download the whole folder at once (as in Google Drive). You had to select all the files (thankfully, you could do Ctrl+A to select all files), and then download them. And when you press download, they’ll all start downloading one by one. I managed to set the default action to download without opening, and the default download folder to the kaanu folder on my computer to be able to download the whole folder without crashing.
Yet, after downloading everything, there were about 200 files missing. Turns out when a browser makes so many network requests, some of them fail. Even when I downloaded files in batches of 100-200, there were failures.
To resolve this, I decided to compare the list of files online and the list of files on my computer to find which ones were missing. I had to make LLMs write out some javascript that I could run in the console while on icloud.com to fetch all the filenames (using aria-value). Then I used this in a python script to compare the ones locally present, thus obtaining a list of files remaining to be downloaded. And those I downloaded one by one.
Once I had all the files, I also rsync’ed the whole folder to the server to serve PDFs directly to visitors.
Extraction
With all PDFs available on my computer, I just had to extract the keywords from each for the next step.
Fortunately, at the beginning of this process months ago, I had verified that the keywords can be extracted using pypdf, with a sample PDF that was shared by WS.
I used the same python script iterating in a bash loop to output filename, link, and keywords to a CSV file.
Tomorrow, comments can also be added as another column.
Inserting to Obsidian
With the annotations neatly packed in a CSV, I just had to create the correct markdown notes using another python script.
We created a node for each keyword, and a node for each publication.
The publication node would be linked to each keyword that applies to it. It would also have a link to the PDF itself.
I tried embedding the PDF directly using an iframe, which worked for firefox, but failed on Chrome. So for now I have chosen to embed the PDF using Google Docs viewer.
Publishing
The graph view that Obsidian Publish provides is the biggest reason we were using Obsidian. We did look for alternatives that we could self-host. Quartz could have worked, but it was very slow in development and building so many pages.
Therefore we decided to just use Obsidian Publish itself. Obsidian Publish is incredibly fast in comparing and publishing changes.
And with that we had the beautiful graph linking all kinds of publications with all kinds of keywords.
The last day scramble
So, the plan was that WS would annotate as many PDFs as possible till 1 day before the launch, and then I would run the rest of the workflow on the previous day of the launch.
At 07:48 AM on 21st WS sent the go-ahead message on Slack:
@all Reached 860 curated publications, cleaned and with keywords, ready to be uploaded @Akshay S Dinesh They’re all on my iCloud. Please start downloading & importing in Obsidian. Yes, we can!
What WS didn’t know was that the previous evening, my laptop had stopped charging. The LC 230 that I use has been struggling with a loose charger port for a while now. And as luck would have it, it finally gave up on this day. I had given the computer for repair, and it would be back only by evening of 21st.
So, I had to set up WSL and python and the whole environment on Swathi’s laptop to run the workflow on the last day.
I was hoping that the iCloud app for windows would make my life easier. But turns out, you can’t use that app unless you set up iCloud on a Mac device first! So, back to manual downloading.
And by about 4:30 that evening, I had the whole workflow run and the site ready for launch. Shortly thereafter, the service center called me saying my repaired laptop was ready for pickup.
The launch
Within 20th year anniversary day of IPH, 22nd August 2025, it was launched for public. There was a TV setup outside in which Werner demonstrated and spoke about the site to everyone who stopped by.
You can also visit it on your computer by going to kaanu.org.
When you visit the site from a desktop/laptop browser, on the top right you can see an “Interactive Graph”. Press the button called “Global Graph” on the top right of this graph, and you can see and play with the galaxy of nodes for yourself.
The second workflow
After the launch, Werner and I met to fix the workflow.
For the most painful part of synchronizing files, we decided to use syncthing. With syncthing set up on WS’s computer and on the server, all changed files would immediately be synced to the server directly.
And I could set up the python scripts on the server itself such that the obsidian files would also be ready on the server.
Since Obsidian Publish doesn’t have a CLI, I plan to use syncthing again to sync that folder to my computer and use the GUI to publish the site. This allows Prashanth also to continue using Obsidian by synchronizing with the syncthing folder.
Conclusion
All of this might look like a scrappy way to do something so straightforward. But it works. And that’s enough for now.
Subscribe to my Substack Newsletter
As you might have noticed, social media these days prioritize engagement and doesn’t really let people build relationship with an audience. One way to take back some control is to directly be connected to your favorite authors, artists, etc through e-mail. And that’s what subscribing to my newsletter is about, too. I’m intentionally staying away from substack (which is susceptible to enshittification), and self-hosting the newsletter. What that means is also that the mails could land in spam. So, please press “Not spam” if they do end up in spam. Thank you!
You can fill your details below
↓